How Zutty works: Rendering a terminal with an OpenGL Compute Shader
Observing the rise of Alacritty and Kitty, I had to concede that hardware-accelerated terminal emulators had clearly become a thing. As a heavy user of the humble text terminal, I am naturally interested in such fresh perspectives on this several decades old UNIX-ism. Somewhat surprisingly, after trying both of these programs, none of them turned out to be the technological facelift I was looking for – and none of them work on my low-spec single-board computer, since they require “desktop” OpenGL while my ARM Mali GPU only supports OpenGL ES. The critique of these programs is for a later post; here I want to talk about something more fundamental.
If you would set out to create the theoretically most efficient way of rendering the content of a text terminal to a window image, how would you go about it?
That is, how would you transform a grid of text (a two-dimensional array of characters, possibly enhanced with attributes such as color) into a pixel image?
Well, you would of course use some hardware rendering running on your massively parallel GPU (written in OpenGL or similar on the source level). The real question is, what would be the most elegant and possibly also the most performant way of doing exactly that?
The traditional way of OpenGL text rendering taught by several online tutorials – namely, one that effectively renders characters one-by-one, accumulating projections of glyphs from an atlas texture to the output surface by filling up a Vertex Array Object, sequentially traversing the string of characters to be rendered on the CPU side – is the basic algorithm still employed by both Alacritty and Kitty. Could one think of a vastly more elegant, and even potentially more performant way to render a screenful of a text terminal, all at once?
Yes indeed. To recognize the possibility of mass vectorization (and hence parallelization) of the job of rendering the contents of a text terminal, observe that it has regular geometry: it is a uniform grid of identically spaced character cells laid out in a number of rows and columns. Each cell of this grid is capable of displaying (at first approximation) a single glyph, that is, the image associated with a character code (as defined by the font face in use). Each cell has the same size, so why spend precious CPU cycles computing vertex coordinates, atlas mappings (since both the source font glyphs and the destination cells are equally sized), and why spend bandwidth pushing these to the GPU on each update?
The minimal host-GPU interface
Let’s start from first principles. To represent the information displayed by the terminal, one could naturally think of it as a two-dimensional array of cells, where each cell contains the essential properties associated with a grid location, namely, the character being displayed, plus several attributes:
struct Cell
{
uint16_t charCode; // Unicode code point
uint16_t flags; // Bold, italic, underline, inverse video, ...
Color foreground; // Three bytes for red, green, blue components
Color background;
};The screen can be modeled simply as an array of such Cells. We can think of this array as two-dimensional (ranked by the number of rows and columns of the terminal display), but implementation-wise, it is even simpler to have just one single array of all the cells:
struct Cell cells [nRows * nCols];In this contiguous array of storage, we agree to store cells in a
certain well-defined order: the cell at grid position (row,col) is
going to be stored in the array slot cells [nCols * row + col].
It is trivial to write a virtual terminal implementation that will read a stream of bytes coming from a shell program (carrying the characters to be displayed, as well as escape sequences for controlling various aspects of the output) and manipulate this array of cells to represent the right display content. In fact, such manipulation represents the minimum amount of work any virtual terminal must do to maintain state.
Given the above, we postulate that this is exactly the interface where the virtual terminal (on the host CPU) and the graphical display engine (on the GPU) should meet. (We are simplifying over some non-essential details: cursor display, mouse selection support, multiple fonts to support bold, italic and boldItalic… but this has no real bearing on the core idea.)
So, where do we put our array of cells (with Unicode character codes for each position, so no CPU cycles spent on mapping them to atlas coordinates or anything like that!) and automagically get a fully complete, displayed terminal screen out of it?
Simple: we put cells [] directly in GPU memory, allocated as a
Shader Storage Buffer Object (SSBO). This way, the virtual terminal
can manipulate the array directly via a mapping into its process
address space, while also being directly available to OpenGL shaders.
The responsibility of the host program ends with maintaining the right
content in this array of cells. Everything else is done on the GPU!
Zutty: a proof of concept
To prove that this is possible, I wrote my own terminal emulator built on exactly this architecture. It is called Zutty and here comes a high-level overview of how its GPU-based rendering works. (Mind you, Zutty is actually much more than a bare proof of concept for this idea: it is a fairly capable terminal emulator in its own right, so if it fits your bill, feel free to start using it for your daily work right now.)
Zutty employs the Compute Shader, which is a really efficient way to make use of the truly massive parallelism offered by contemporary graphics hardware. A nice attribute of the Compute Shader is that it is not tied to the classical graphics pipeline operating on vertices or screen fragments; you are basically free to come up with the slicing and dicing of your problem space in a way that makes sense for your problem.
As it turns out, there is a natural way to slice and dice our problem
of rendering the terminal output: one independent rendering process
per cell. Observe that the input of each cell is independent of all
others, and the same can be said of its output. We can thus define how
to render a single cell at grid position (row,col) based on the
content of cells [nCols * row + col] (remember that this array is
already on the GPU, ready to be read by our compute shader).
Then, for each screen update, we only need to launch a GPU-based
computation (an OpenGL compute program) for all grid locations: a
matter of calling DispatchCompute with the dimensions of our
terminal grid (nCols, nRows) as arguments.
The below image demonstrates the rendering dataflow for a single compute instance.
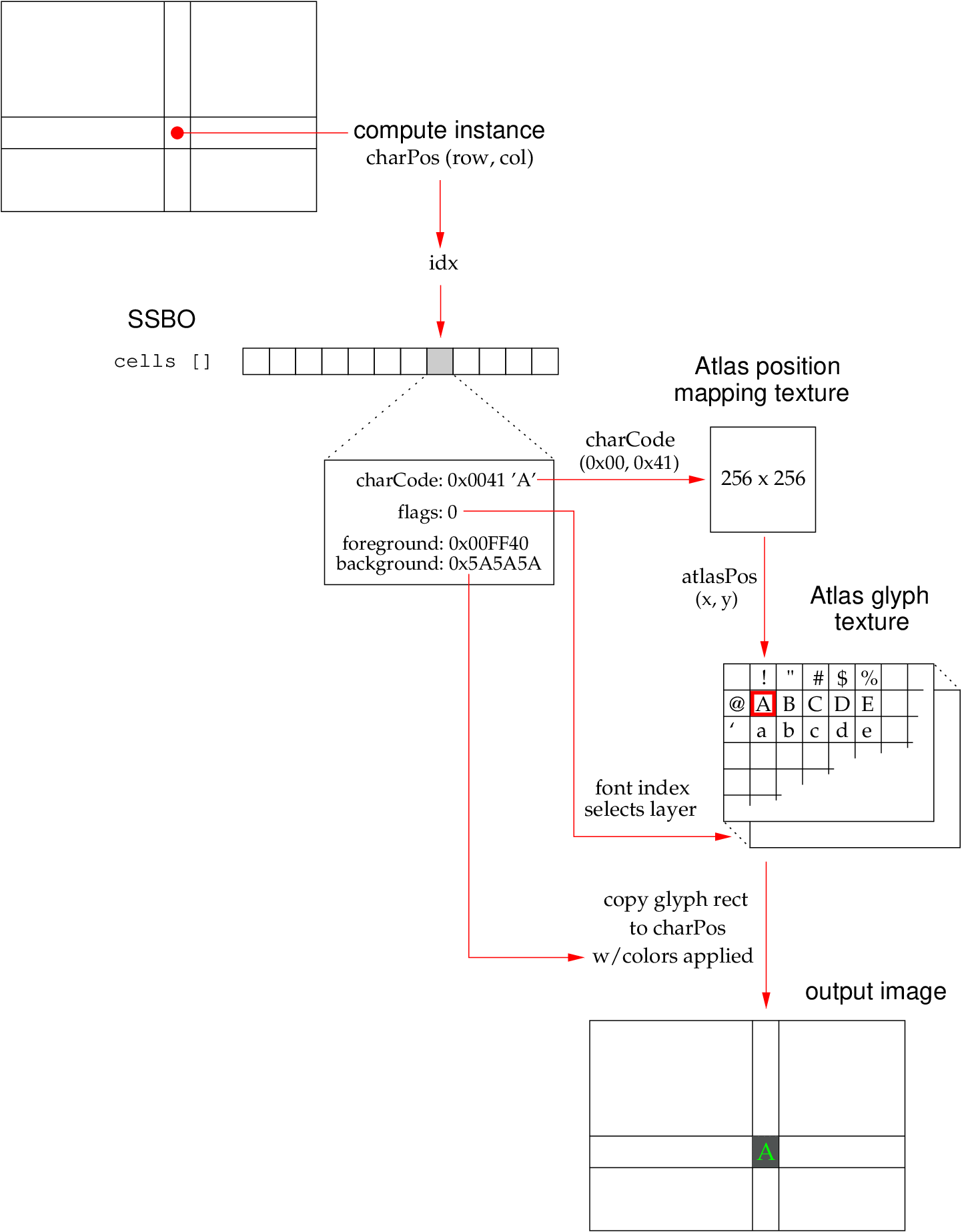
Compute Shader of Zutty – GPU-based rendering dataflow
It all starts with the input array cells []. In the compute
program, we can easily retrieve the actual character grid coordinates
of the cell being rendered by this program instance: they are equal to
the coordinates of the compute instance itself (called
GlobalInvocationID in OpenGL-speak) by virtue of the above, trivial
slicing-and-dicing that we have done.
charPos = gl_GlobalInvocationID.xy;
idx = nCols * charPos.y + charPos.x;
Cell cell = cells [idx];The charPos vector allows us to access the cell, with all its
properties, in the array of cells residing in the SSBO. We extract the
16-bit Unicode character code as two bytes, to address a 256x256-sized
texture containing the atlas position mapping. This mapping texture is
computed and stored on font loading and initialization, and is
read-only from the perspective of the graphics program. Each texel
(texture element) is another two-byte value, containing a
two-dimensional vector used to address the atlas glyph texture. This
texture, in turn, contains the rasterized glyphs of each code point
supported by the font being used.
atlasPos = texelFetch (atlasMap, charCode);Given the atlas texture position of the glyph to render, we only need to copy the pixels of the corresponding rectangular area from the glyph texture to the output image. Since all of these rectangular grid cells are sized equal to the glyph dimensions, this is a trivial pixel-for-pixel copy operation.
There are a small number of details omitted here. The compute program considers other cell attributes such as foreground and background color, and sets output pixel color values based on these inputs. Font attributes (bold, italic) act as a layer index into a multi-layered atlas texture storing all loaded font variants. The cursor has to be separately rendered on top. But the above tiny pseudo-code is the essence of it, and the complete truth is in fact not much more complicated.
If you are interested in how this architecture allows Zutty to perform in comparison to other terminal emulators, read my follow-up posts A totally biased comparison of Zutty as well as Measured: Typing latency of Zutty.