Payment matching done right
I use ledger to keep an accurate record of my finances. All those financial actions of receiving, spending, saving, investing or moving around money will be reflected by transactions in my ledger file. If you have ever tried to do anything similar, you might think that maintaining the ledger is cumbersome, time consuming and error-prone. In reality, nothing could be further from the truth. You need proper tooling, though.
Any half-decent bank will provide access to your account history as some kind of downloadable CSV (or maybe an Excel file that can be converted to CSV fairly easily). Each entry in the CSV has fields for the transaction identifier, a date (or maybe two, if they separate the value date from the transaction date), the amount and some text which aims to identify what the transaction was or who the counterparty is.
As it turns out, the only real question when converting all this into a ledger entry is finding the correct counter- (or payee-) account of each transaction. I say counter-account, because the account itself is known: it is the representation (typically an Asset in accounting lingo) of the very account that the history pertains to.
Since I started keeping all my financial records in double entry bookkeeping, I tried a few different solutions. First I used GnuCash, but that proved to be a horrible experience when importing my account statements. I basically had to choose the payee account from drop-down menus in the import wizard on a per transaction basis. I also disapproved of the XML file which looked unnecessarily complicated and got quite large.
Then I migrated my books to ledger and never looked back. Finally I
felt in control of the whole flow: a simple text file is all I need to
maintain. So I adapted my importer scripts (by this time I had a few,
initially to convert CSV/XML to QIF that I could import into
GnuCash). However, the problem of finding the right account to write
the bookkeeping remained unsolved. I tried a few alternatives (ledger
--xact, reckon, etc.) but none seemed to work reliably enough.
This got me thinking about the underlying problem. What is the best algorithm for matching a bank account transaction to a bookkeeping account?
The matching algorithm
Assuming you have any sort of financial history in your ledger, you
have most likely already invented a number of bookkeeping accounts to
label the sources and sinks of your money. For example Income:Salary
is where your salary comes from, and Expenses:Rent is where each
month’s rent payment is booked. When adding new transactions, they
will most likely fall in one of the existing categories, since they
will be, for the most part, new instances of recurring transactions
you already have in your books (like paying the rent, or shopping once
again in your favourite grocery store). When considering a new
transaction to be added to your ledger, the fundamental question is
this: which of these bookkeeping accounts should be chosen as the
counterparty?
Preferably, this should be decided with no up-front configuration such
as regex rules or anything like that. I also don’t want the algorithm
to ask me any questions. I will adjust the generated entries anyway,
fixing anything I might not like, so guessing is fine as long as the
guesses are reasonably good. What’s more, I want the tool to
automatically adapt to any changes I might enact on the ledger. So if
I decide that from now on, the rent is bookkept under
Expenses:Housing (and run an auto-search-replace for that in my
whole ledger file), this change should be picked up by the algorithm.
So how to do this? I use the following naive Bayesian inference algorithm.
Step 1
Parse the ledger file. For each account, maintain a table of {token→N} entries, increasing the tally for all the tokens from the descriptor text in the table for that account.
Also, add each token to the set of all tokens T and each account to the set of accounts A, so we have these sets ready for the subsequent steps where we will iterate over them.
Let N(t,a) be the number of occurrences of token t in account a.
Step 2
When parsing a new transaction, scan the descriptor into tokens. Based
on the presence of each token, a vector of probabilities of the
transaction belonging to each possible account is calculated. Let
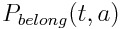 be the probability that a
transaction with the token t belongs to account a.
be the probability that a
transaction with the token t belongs to account a.
We define as:
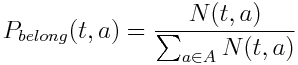
Then, after we have
for all tokens in the descriptor for all accounts, we use the Bayes
theorem to calculate the combined probability of the transaction to
belong to the accounts.
Let P(a) be the probability of the descriptor to correspond to account a. For each account, P(a) is defined as:
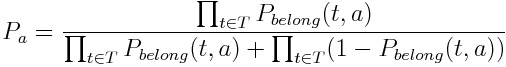
Then, the account with the greatest P(a) should be chosen.
Note that step 1 does not depend on the transaction to be decided on, just the current ledger file. The results of reading the ledger file may thus be precomputed and then only the remaining part of the algorithm needs to be carried out on a per transaction basis.
The implementation
My implementation is done in Clojure, which I consider one of the most promising new languages. Clojure is my personal favourite among these. (My other favourite languages, Erlang, Common Lisp and C, are not exactly new.)
The repository is among my public repos, called banks2ledger. Read the repository README for general instructions and usage.
One interesting point I want to make here is the way tokenizing is
done. It is super simple but improves the quality of the matches
quite a bit. When breaking the transaction’s description string into
tokens, by default every substring separated by spaces
(i.e. conventional words) will be a token. (The tokens are not case
sensitive, so everything is converted to uppercase.) The comma , and
the slash / are also taken as token separators.
What’s more, different forms of dates are replaced with degraded forms. This is because the same recurring transaction will show up with different dates in the ledger file; we want all these, and even future dates, to weigh towards the same payee account (in terms of Bayesian inference). So a substring like “20160317” will be replaced by the generic (degraded) token “YYYYMMDD”. The same goes for dates specified as “YY-MM-DD”. In practice, it is these two formats pertaining to card transactions that I have come across.
One final quirk: when editing the newly added transactions in my
ledger file, I will sometimes add some notes after the end of the
original descriptor string. I separate these notes with a pipe |
character from the original content that came from the bank account
CSV. The notes contain additional information concerning the
transaction that I want to be able to look up later. But since this
part does not come from the original CSV, it is not useful to parse it
when tokenizing. So when descriptor lines are read from the ledger
file, any pipe character terminates the line.
Driving the flow
Each month I download the account history CSV (or XLS) from all the
banks I have accounts with. I save all these files according to simple
naming conventions (i.e. bankname_YYYY_MM.csv) and archive them
indefinitely for further reference.
After downloading the account files for the recently closed month, I
run make which will drive the conversion of all the account files
into ledger format. These files will be saved with the same names as
the originals, changing the extension to .dat.
Below is the Makefile I currently use. (Note that in two cases I
download the file as XLS or even XLSX and convert that to CSV via
ssconvert, a useful command line tool that comes with Gnumeric). The
JAR file run by make is the result of running lein uberjar in the
banks2ledger repo. It is a standalone executable version of my
Clojure application.
dats := $(patsubst %.xls,%.dat,$(wildcard *.xls))
dats += $(patsubst %.csv,%.dat,$(wildcard *.csv))
dats += $(patsubst %.xlsx,%.dat,$(wildcard *.xlsx))
all : $(dats)
LEDGER ?= "/home/tom/doc/ledger/ledger.dat"
B2LJAR ?= "/home/tom/bin/banks2ledger-1.0.0-standalone.jar"
bp_%.dat: bp_%.csv
java -jar $(B2LJAR) -l $(LEDGER) -f $< -sa 3 -sz 2 -D 'yyyy/MM/dd' \
-r 3 -m 4 -t '%9!%1 %6 %7 %8' -a 'Assets:Budapest Bank' -c HUF > $@
seb_%.dat: seb_%.csv
java -jar $(B2LJAR) -l $(LEDGER) -f $< -sa 5 -r 2 -m 4 -t '%3' \
-a 'Assets:SEB Privatkonto' > $@
ica_%.dat: ica_%.csv
java -jar $(B2LJAR) -l $(LEDGER) -f $< -F ';' -sa 1 -m 4 -t '%1' \
-a 'Assets:ICA Bank' > $@
bp_%.csv: bp_%.xls
ssconvert $< $@
seb_%.csv: seb_%.xlsx
ssconvert $< $@
After the conversion is done, I go through the resulting .dat files
and manually edit them as I see fit. When that is done, I append them
to my main ledger file and eventually, if everything looks fine,
commit the changes to that file. The .dat files are also archived
along with the sources.
Executing this flow takes about half an hour each month – including
logging in to all webbanks and downloading the account history files,
running make which in turn runs banks2ledger on all of them, and
finally reviewing and editing the results, committing the updated
master ledger to git. In return, I get detailed records of all my
money movements, which I find to be an indispensable resource.